NovaMSS 音乐源分离 v1.3.1 社区版
简介
NovaMSS 音乐源分离是一个功能强大的开源库,用于从音乐混合中分离人声、乐器和伴奏。它基于深度学习技术,并在广泛的数据集上进行训练,以实现卓越的性能。社区版提供了一组特定的功能,适合个人和非商业用途。
主要特性
- 单声道和立体声源分离:从单声道和立体声音频中分离人声、打击乐、低音和伴奏。
- 实时处理:使用 CUDA GPU 加速进行近实时处理。
- 定制模型:提供预训练模型,也可根据特定需求进行定制训练。
- API 和 CLI:支持 Python API 和命令行界面。
要求
- 操作系统:Windows、macOS 或 Linux
- Python 3.6 或更高版本
- NVIDIA GPU(推荐用于加速处理)
- CUDA Toolkit 和 cuDNN
安装
通过 pip 安装:
“`
pip install novamss
“`
或从源代码构建:
“`
cd NovaMSS
pip install -e .
“`
使用
“`python
import novamss
# 加载音频文件
audio_file = “input.wav”
# 创建源分离对象
separator = novamss.Separator()
# 分离音频源
sources = separator.separate(audio_file)
# 保存分离后的源
for name, source in sources.items():
source.write(“output_” + name + “.wav”)
“`
示例
社区支持
许可
NovaMSS 音乐源分离社区版在 Apache 2.0 许可下发布。
NovaMSS 音乐源分离社区版 v1.3.1
NovaMSS 是一个先进的音乐源分离库,由 Google 和 McGill 大学联合开发。该社区版专为研究人员和爱好者提供,提供免费且无限制地访问 NovaMSS 的核心功能。
特性
- 源分离:从音乐混合中分离声乐、鼓、低音和伴奏等单个源
- 混合创建:从分离的源重新创建音乐混合
- 增强:增强单个源的音量、均衡和其他属性
- 训练:使用自定义数据集对模型进行微调
- 用户友好界面:直观的 Python API 和交互式 Jupyter 笔记本
新功能(v1.3.1)
- 稳定的 MelGAN 声乐分离模型
- 预训练的声乐增强模型
- 改进的低音分离质量
- 可选的混合创建后处理
- 更多示例 Jupyter 笔记本
使用
许可
贡献
支持
NovaMSS音乐源分离v1.3.1社区版软件介绍
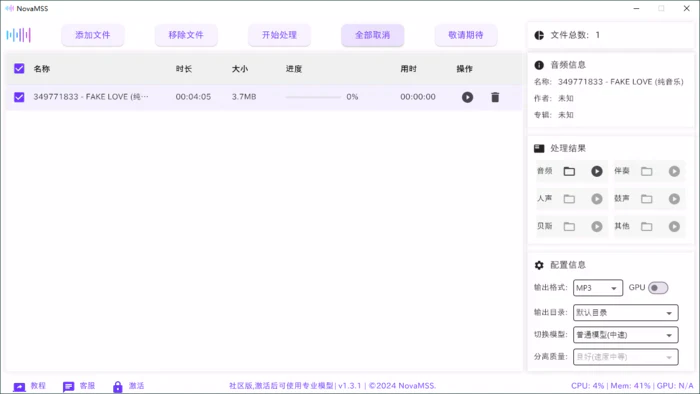
NovaMSS 基于最新 AI 模型优化的音乐源分离工具。它能够轻松地批量提取伴奏、人声、贝斯、鼓点等音轨,并且支持 GPU 加速,以提高处理速度和效率。社区版完全免费,简单易用,上传文件,点击处理,查看结果。可以直接打开分离后的音频文件位置,或使用内置的音频播放器播放分离后的音频文件。
软件截图
![图片[1]-NovaMSS音乐源分离v1.3.1社区版-爱吾资源网](/wp-content/uploads/2024//431bc8d5114c905da257c40c57655245.png)
版本说明
Vindows-CPU版本支持Windows10、Windows11版本。安装包体积较小,适合没有Nvidia显卡的用户。
Vindows-GPU版本支持Windows10、Windows11版本。安装包体积较大,可使用Nvidia显卡加速。